Unsupervised learning#
When working a dataset having dependent and independent variables but no class labels then we can train a machine learning model using unsupervised learning algorithms. Clustering of data is an example of unsupervised learning because here we group the data points without having any specific name for each group. The sklearn library has various algorithms for unsupervised learning. Here we’ll walk through the kmeans clustering algorithm using the iris dataset which contains data for four different parameters from three species of iris plant.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.cluster import KMeans
You can either download the iris dataset as a csv file and read it in a dataframe using read_csv function or directly load the dataset using the URL to create a new dataframe using the same function. We’ll load the iris data using the second option. In this data there are no headers i.e. there are no column names, so we’ll also create a list having the appropriate column names and pass is as an argument to the read_csv function.
csv_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
col_names = ['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width','Class']
iris = pd.read_csv(csv_url, names = col_names)
iris
#iris.shape
| Sepal_Length | Sepal_Width | Petal_Length | Petal_Width | Class | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
150 rows × 5 columns
Data pre-processing#
Create x and y matrices having the observations and labels respectively. The x matrix would comprise of only the values of all the features for all the samples. This would be used for training the machine learning model. The y matrix would have the labels correponding to the samples in the x matrix. The y matrix is used in supervised classification. The x matrix is a 2d array with shape n_samples by n_features while the y matrix is a one dimensional array.
iris.columns[:4]
Index(['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'], dtype='object')
iris.loc[:,iris.columns[0:4]]
| Sepal_Length | Sepal_Width | Petal_Length | Petal_Width | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
150 rows × 4 columns
x = iris.loc[:,iris.columns[0:4]]
y = iris.loc[:,"Class"]
print(x.shape)
print(y.shape)
(150, 4)
(150,)
y
0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
4 Iris-setosa
...
145 Iris-virginica
146 Iris-virginica
147 Iris-virginica
148 Iris-virginica
149 Iris-virginica
Name: Class, Length: 150, dtype: object
Standardization of data and label encoding#
x_standardized = StandardScaler().fit_transform(x)
x_standardized[:5]
array([[-0.90068117, 1.03205722, -1.3412724 , -1.31297673],
[-1.14301691, -0.1249576 , -1.3412724 , -1.31297673],
[-1.38535265, 0.33784833, -1.39813811, -1.31297673],
[-1.50652052, 0.10644536, -1.2844067 , -1.31297673],
[-1.02184904, 1.26346019, -1.3412724 , -1.31297673]])
y = LabelEncoder().fit_transform(y)
y
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
# Alternate approach
#iris["Class"].replace(['Iris-setosa', 'Iris-versicolor','Iris-virginica'], [1,2,3]).values
Model building#
Next, a machine learning model would be built using the kmeans algorithm to predict the labels of the data i.e. the x matrix. This is achieved by instantiating a KMeans object with required arguments. The n_cluster keyword argument specifies the number of clusters that we want. In Kmeans jargon this number specifies the number of centroid to generate. the default value for this is 8. For our data we’ll set its value to 3 because we know that the data is from three species. In case we don’t know how many clusters to expect, we can figure that out using the elbow method which we’ll cover in a while. The init argument is for initializing the positioning of the centroids. We can set the initial position based on an empirical probability distribution of the data points using the k-means++ or we can also specify the exact location for initial positioning of centroids. The n_init and max_iter arguments refer to number of independent runs of the kmeans algorirhtm and maximum number of iterations of the algorithm in each run, respectively. Setting the random_state argument to an int ensures the reproducibilty of the results.
Once we have instantiate a KMeans object, we can use the fit_predict function to first fit the data to the model, and then predict the label of the given data. It returns an array of labels corresponding to the each data point (sample).
kmeans = KMeans(n_clusters = 3, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0)
# fit and predict
y_kmeans = kmeans.fit_predict(x_standardized)
y_kmeans
C:\ProgramData\anaconda3\Lib\site-packages\sklearn\cluster\_kmeans.py:1446: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=1.
warnings.warn(
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 2, 2, 2, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 2,
0, 0, 0, 0, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 2, 2, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2,
2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 2, 2, 2, 2, 2,
2, 0, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0])
The fit_predict function returns the predicted index of the cluster corresponding to all the data points. Note that this function is effectively a combination of two functions – fit and predict.
Once the data has been fitted to the KMeans object, different output parameters for the model can be accessed through its attributes such as
cluster_centers_to get the coordinates of all the centroidslabels_to get the predicted labels (cluster indices) for the data points.
The predict function can be used to predict the label for a given data point.
#get centers for each of the clusters
kmeans.cluster_centers_
array([[-0.05021989, -0.88029181, 0.34753171, 0.28206327],
[-1.01457897, 0.84230679, -1.30487835, -1.25512862],
[ 1.13597027, 0.09659843, 0.996271 , 1.01717187]])
#predicting the cluster of an unknown observation
kmeans.predict([[-0.90068117, 1.03205722, -1.3412724 , -1.31297673]])
array([1])
Compare the predicted labels with the original labels#
When the data is fitted to the KMeans model, the predicted labels could be in any order i.e. the cluster are numbered randomly. Therefore, direct mapping of the predicted labels and original labels could result in misleading interpretations of the prediction accuracy. So, to compare the predicted cluster with the original labels, we need to take into account this characteristic of the clustering function. The adjusted_rand_score function compares the members of different cluster in context of the cluster labels.
print(y)
print(kmeans.labels_)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 0 0 0 2 0 0 0 0 0 0 0 0 2 0 0 0 0 2 0 0 0
0 2 2 2 0 0 0 0 0 0 0 2 2 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 2 2 2 0 2 2 2 2
2 2 0 0 2 2 2 2 0 2 0 2 0 2 2 0 2 2 2 2 2 2 0 0 2 2 2 0 2 2 2 0 2 2 2 0 2
2 0]
from sklearn.metrics import adjusted_rand_score
adjusted_rand_score(y, kmeans.labels_)
0.6201351808870379
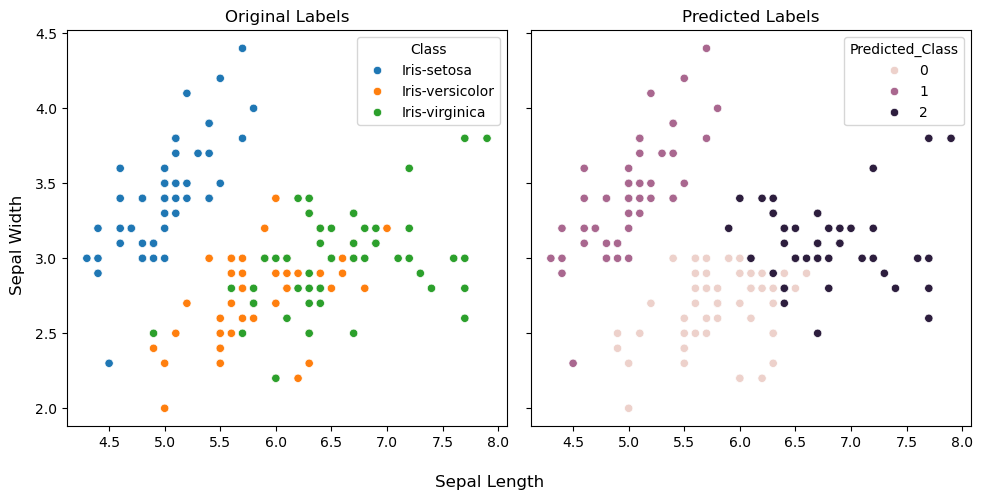
To perform the visual assessment of the predictions, let’s plot the clusters using first two features. This way it would be convenient to see the differences in the original and predicted labels in a two-dimensional graph. We’ll first create a copy of the iris dataframe and add a new column which would hold the predicted labels. Subsequently, the scatterplot function from the seaborn library for plotting and the coloring of the data points would be based on the class labels (original and predicted separately).
iris_predicted = iris.copy()
iris_predicted["Predicted_Class"] = y_kmeans
iris_predicted.head()
| Sepal_Length | Sepal_Width | Petal_Length | Petal_Width | Class | Predicted_Class | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa | 1 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa | 1 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa | 1 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa | 1 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa | 1 |
fig, ax = plt.subplots(1,2, figsize=(10,5), sharey=True)
ax[0].set_title("Original Labels")
sns.scatterplot(data=iris_predicted, x="Sepal_Length", y="Sepal_Width", ax=ax[0], hue="Class")
ax[0].set_xlabel("")
ax[0].set_ylabel("")
ax[1].set_title("Predicted Labels")
sns.scatterplot(data=iris_predicted, x="Sepal_Length", y="Sepal_Width", ax=ax[1], hue="Predicted_Class")
ax[1].set_xlabel("")
fig.supxlabel("Sepal Length")
fig.supylabel("Sepal Width")
plt.tight_layout()
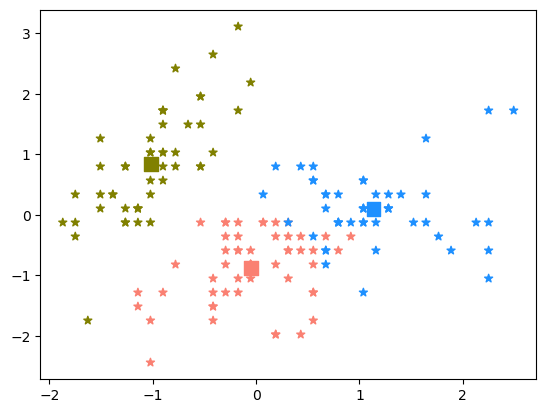
centers = kmeans.cluster_centers_
fix,ax = plt.subplots()
colors = ['salmon', 'olive', 'dodgerblue']
point_colors = [colors[label] for label in kmeans.labels_]
ax.scatter(centers[:,0],centers[:,1], marker='s', s=100, color=colors)
ax.scatter(x_standardized[:,0],x_standardized[:,1], marker="*", color=point_colors)
plt.show()
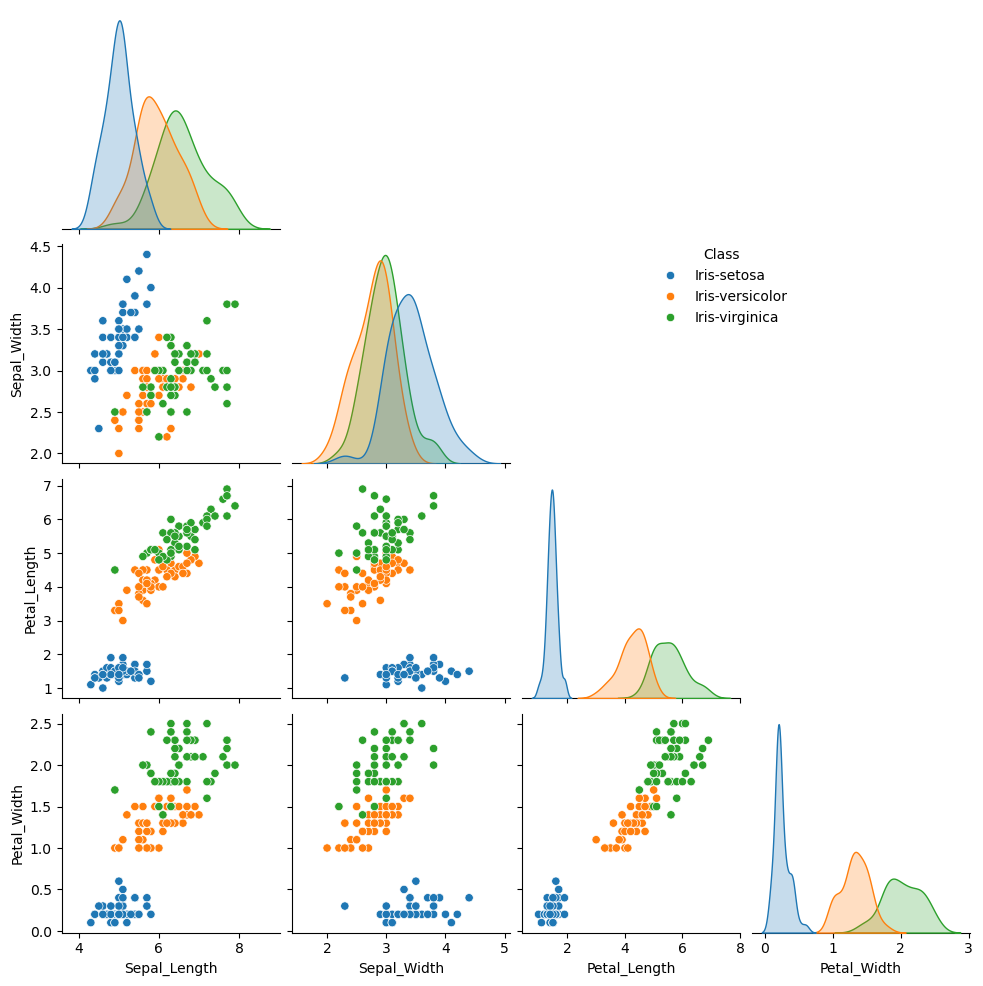
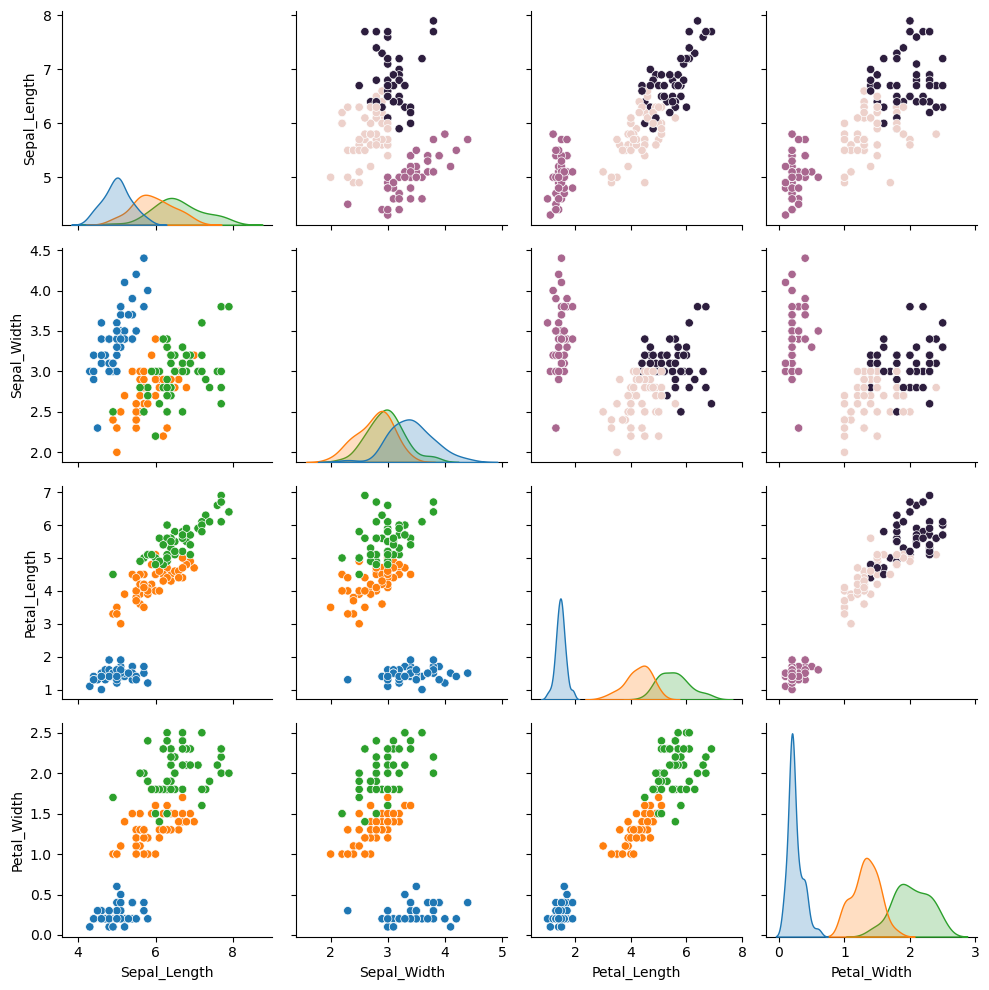
Similarly, we can plot pairwise plot for all the features in the dataframe using sns.pairplot function.
p1 = sns.pairplot(data=iris, hue="Class", corner=True)
p1._legend.set_bbox_to_anchor((0.7,0.7))
#p2 = sns.pairplot(data=iris_predicted, hue="Predicted_Class", corner=True)
Similarly, we can make a pairplot for the predicted labels by replacing iris with iris_predicted and change the hue to Predicted_Class in the above plot. Another, and a better option is to combine the two set of pairplots in one figure – one on the lower triangle and other on the upper. The can be achieved using the PairGrid function in seaborn.
g = sns.PairGrid(data=iris, hue="Class", corner=False)
g.map_lower(sns.scatterplot)
for i, j in zip(*np.triu_indices_from(g.axes, 1)):
sns.scatterplot(
data=iris_predicted,
x=g.x_vars[j],
y=g.y_vars[i],
hue="Predicted_Class",
ax=g.axes[i, j],
legend=False
)
g.map_diag(sns.kdeplot, fill=True)
plt.tight_layout()
plt.show()
Finding optimal number of clusters#
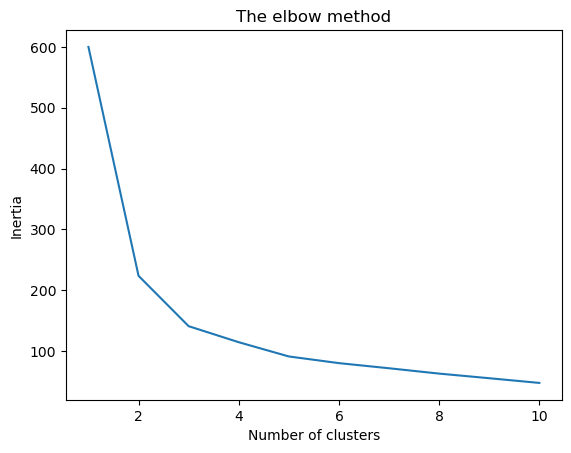
One of the most important hyperparameter for a KMeans object is the n_clusters which stores the value for the number of clusters to create. We can empirically determine an suitable value for this hyperparameter by using the elbow method. In this, we’ll iteratively fit the data to the kMeans objects instantiated with different number values for n_clusters. Algorithmically speaking, the KMeans algorithm select centroids that minimize the inertia (or within-cluster sum-of-squares). In other words, the coordinates for the centroids are such that the sum of distances between each data point (within a cluster) and the cluster center is minimum. Now, upon plotting the inertia values vs the number of clusters, the graph tends to plateau around the optimal number of clusters; which appears like an elbow. As the number of clusters increase there is a decrease in inertia, however, after a certain number of clusters the decrease in inertia is much less compared to what was observed initially. Mathematically, the K-means algorithm operates to minimize the inertia as follows (reference):
where, \(\mu_{j}\) is a cluster center and \(C\) is the set of all clusters. \(x_{i}\) denotes a data point in a given cluster.
kmeans.inertia_
140.96581663074699
wcss = [] #within cluster sum of squares
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', max_iter = 300, \
n_init = 10, random_state = 0)
kmeans.fit(x_standardized)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('The elbow method')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.show()